

Attention Substack users! Most ETO blog posts are also available on Substack.
ETO and CSET analysts often use bibliometric data - data about research publications, like scholarly journal articles or preprints - to map trends in emerging technology areas like AI or cybersecurity. But simple-sounding questions like "How many AI research articles were produced last year?" can be surprisingly difficult to answer.
In large part, that's because there's no universally accepted way to identify "AI articles" to count up. Research publications and journals are most often described in terms of traditional academic disciplines - think biology, computer science, or geology - but those don't include emerging topics like AI. You can search publications for topic-relevant keywords, but that approach tends to be brittle - what if you miss an important keyword, or the words researchers tend to use change over time? Having a subject-matter expert read over papers and sort them into "AI" and "non-AI" buckets might be doable instead, at least for a few dozen papers - but not for the millions of articles in global research datasets like our Merged Academic Corpus.
For the past few years, CSET data scientists have been using machine learning to tackle this problem, developing a set of AI-driven methods to identify research on different emerging tech topics at scale. Recently, we added two more topics to the list: large language model research and chip design and fabrication research. As of this week, both topics are now integrated into all relevant ETO tools and datasets - for example, try searching the Map of Science:
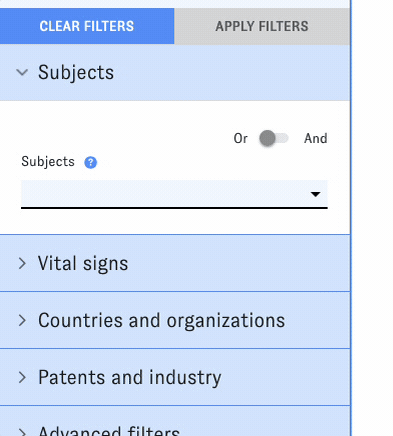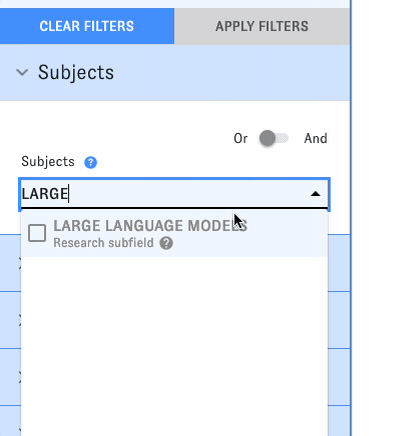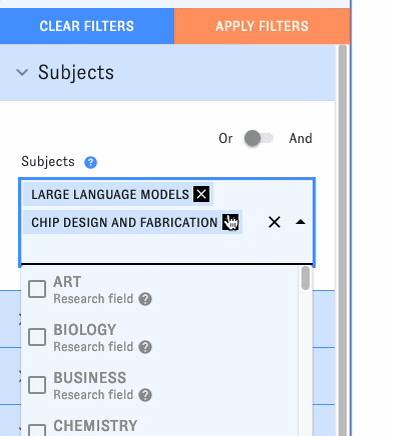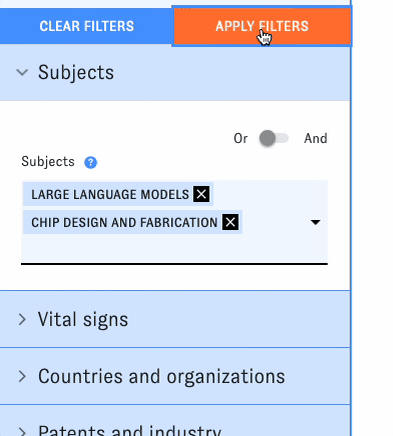
CSET data scientists have used different machine learning methods to track emerging tech research over the past few years, including fine-tuning open-source language models to map AI- and cyber-related research and using weak supervision to develop a model for identifying AI safety articles. For the newest topics, we ran a commercial generative AI model over potentially relevant articles in our Merged Academic Corpus, using a chain of prompts to pick out articles related to each topic. We checked the model's outputs against expert-labeled evaluation sets to confirm that this new approach produced reliable results on par with our prior methods.
For more details on our process for identifying LLM and chip research, including evaluation details, read CSET's recent technical paper Identifying Emerging Technologies in Research. Our public repo has related code and technical details.
Over the next few months, we'll use these new features to explore global trends in LLMs and chip development - be sure to subscribe for the latest analysis. And as always, we're glad to help you get the most out of our resources in the meantime. Visit our support hub to contact us, book live support with an ETO staff member or access the latest documentation for our tools and data. 🤖
This work was supported in part by the Alfred P. Sloan Foundation under Grant No. G-2023-22358.