Overview
What is this tool?
ETO's Open-source software Research and Community Activity (ORCA) tool compiles data on open-source software (OSS) used in science and technology research. Drawing on Github Archive, ETO's Merged Academic Corpus, and several other data sources, ORCA tracks OSS usage, health, development activity, and community engagement across a wide range of software projects and research subjects.
What can I use it for?
Use ORCA to:
- Compare OSS projects in a particular research area according to different metrics of project activity, interest and health.
- Track activity, usage, and community engagement trends over time for specific repos or for all repos in a particular field.
- Sort and filter projects by field, programming language, license, and various activity metrics.
Get updates
What are its most important limitations?
- ORCA assumes some familiarity with OSS. ORCA is designed for users who already know how services like GitHub work (including concepts such as repositories, stars, and commits) and other basics of modern open-source development.
- ORCA focuses on OSS used in published research. It doesn't analyze how OSS is used in domains that produce little or no published research, such as product development in private industry or classified research by governments.
- ORCA only includes data from GitHub repositories. We hope to include other repository hosting services in the future.
- ORCA's method of associating projects with research fields is imperfect. ORCA links OSS projects to research fields primarily using citations to Github repositories in research articles. However, ORCA's data sources don't always include the full text of articles, meaning that we miss some citations. In addition, research articles are assigned to fields using an automated process that may be more reliable for some fields than others. Read more >>
- ORCA only tracks OSS projects that are directly connected to research fields. Some projects may be indirectly important for research through software dependencies. ORCA doesn't currently capture these relationships. Read more >>
What are its sources?
ORCA uses data from Github Archive, the GitHub API, PyPI, The Stack, OpenSSF Scorecards, ETO's Merged Academic Corpus, arXiv, Semantic Scholar, and Papers With Code. Read more >>
Does it contain sensitive information, such as personally identifiable information?
No.
What are the terms of use?
The ORCA tool and metrics are subject to ETO's general terms of use. If you use the tool, please cite us.
How do I cite it?
If you use data from ORCA in your work, please cite the "Emerging Technology Observatory ORCA tracker" and include the link to the tool.
Using ORCA
How do I use it?
Choosing a research field
ORCA is organized by research field. Start by choosing a field from the dropdown menu:
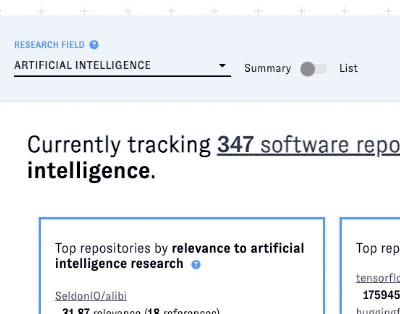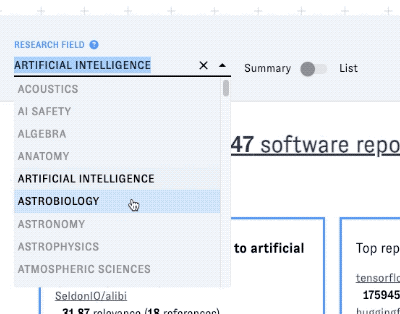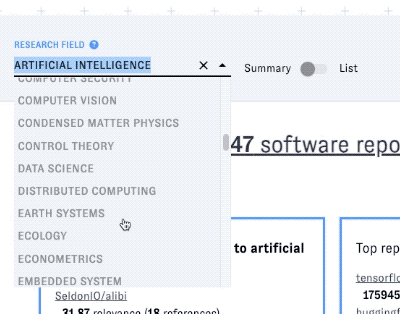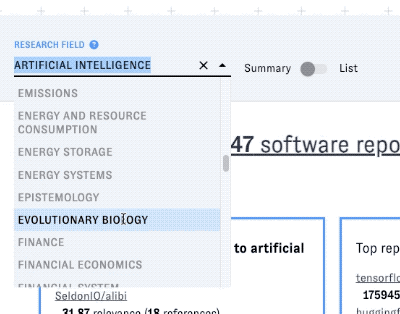
Using summary view to compare top projects in a field
You can browse OSS trends in the selected field with two different views. ORCA defaults to summary view, a condensed view that presents key facts and figures for the top OSS projects associated with the research field you selected. The three boxes list the top projects according to different metrics:

(For more information about these metrics and how we produced them, see our methodology description below.)
Scroll down to view trends over time for the top five projects. You can use the dropdown menu to change the metric used to identify the top projects in these graphs:
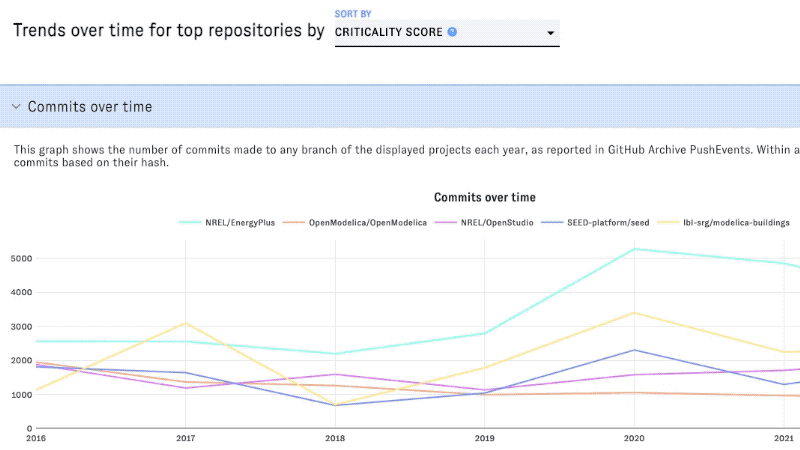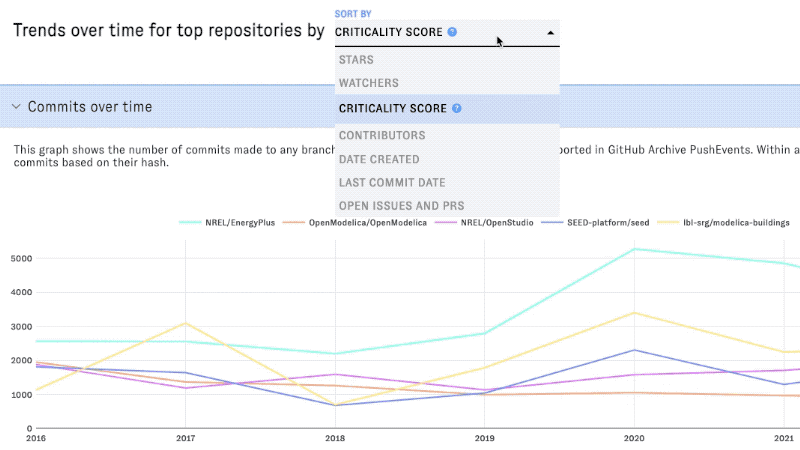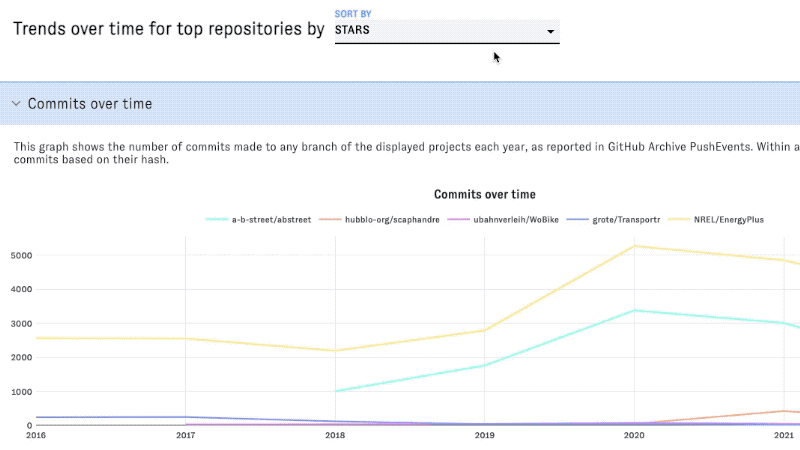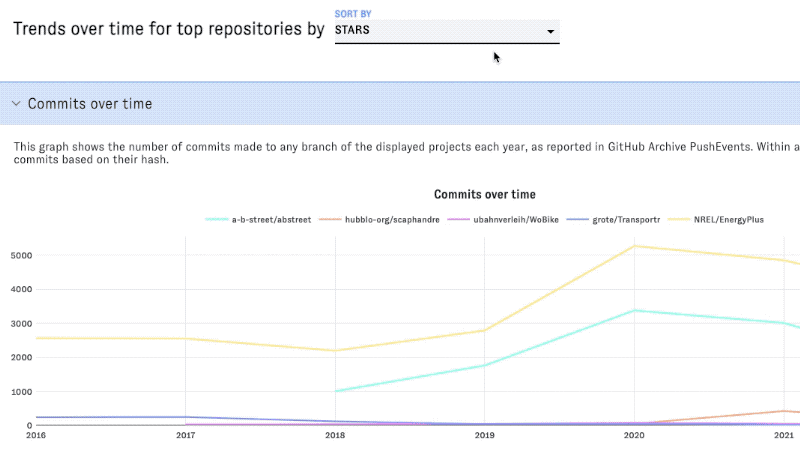
Using list view to browse and compare all projects in a field
Click the view toggle in the toolbar to switch from summary view to list view. This view includes information on every OSS project associated with the research field you selected.
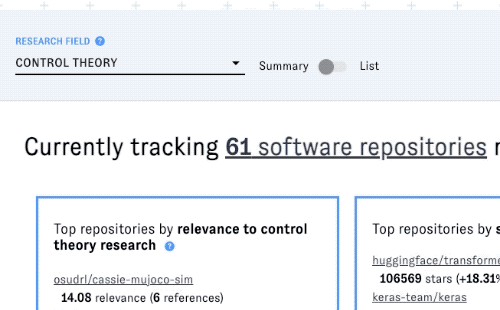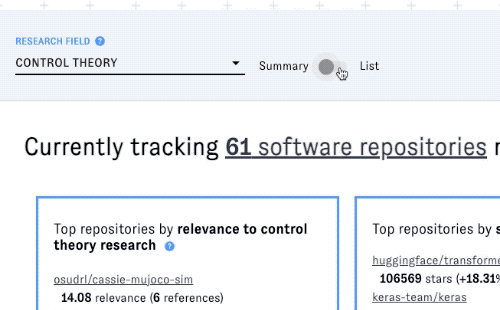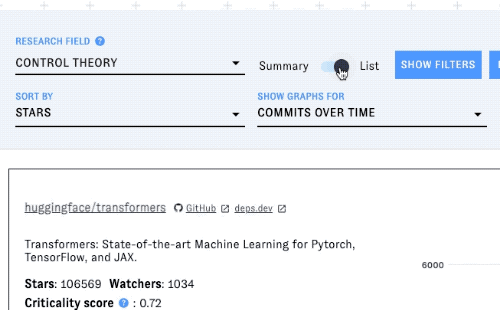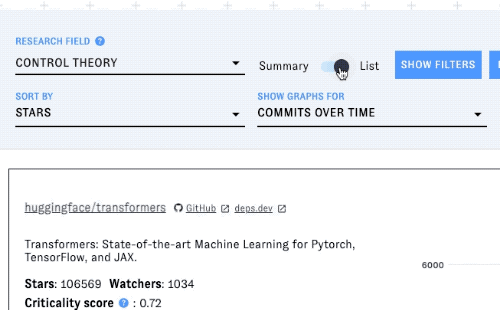
Each project's entry in the list includes a graph displaying a metric over time. Change the metric with the "show graphs for" dropdown.
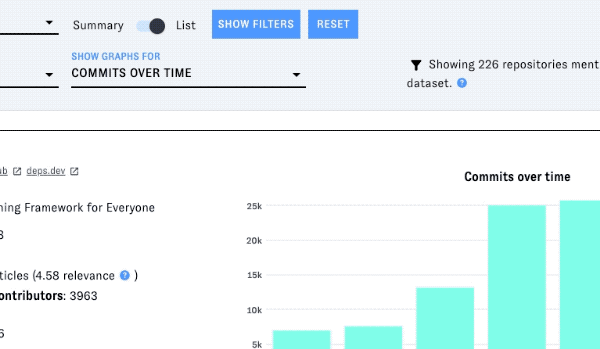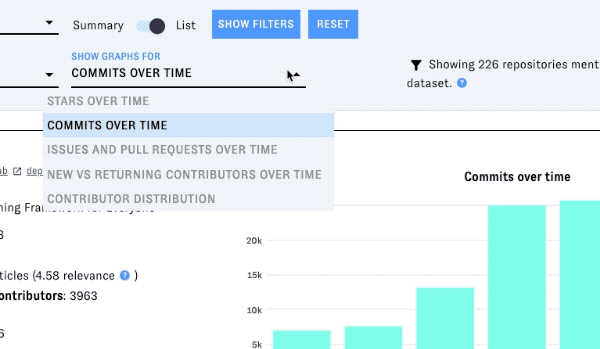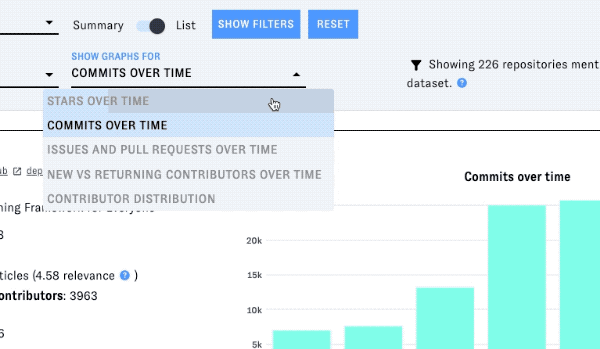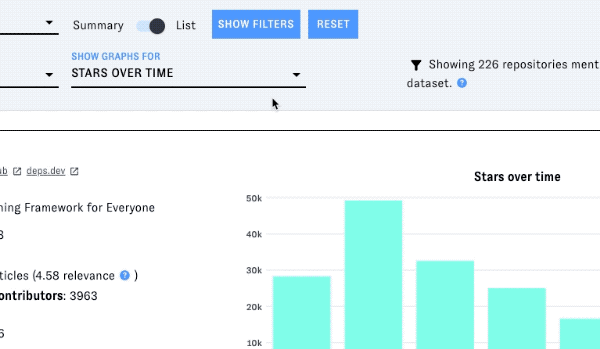
You can also filter the list by license and/or programming language - click on "Show filters" to display the menus for these filters:
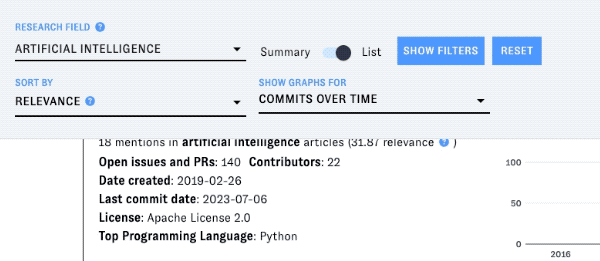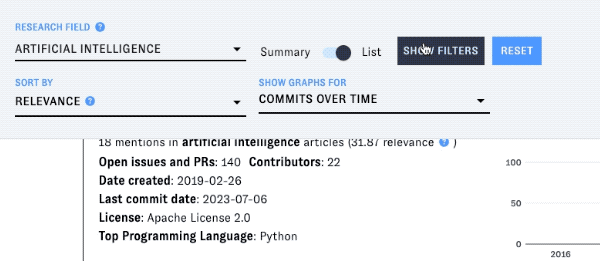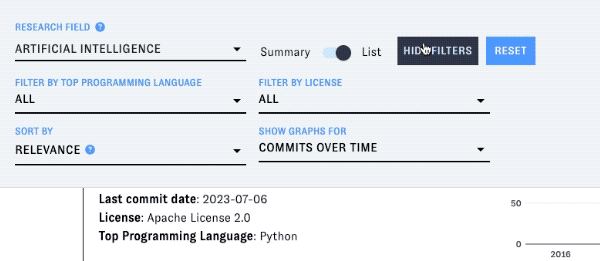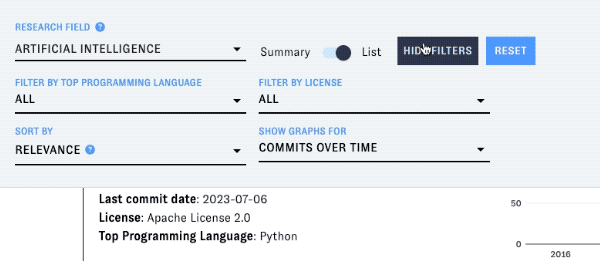
Using detail view to examine a specific project
Click on the "full profile" buttons that appear at the bottom of each repository card in the list view to view all the data in ORCA about that project. The accordion at the bottom of the page includes graphs of different health and activity metrics over time (see below for how these metrics are produced), as well as top-cited articles associated with the project.
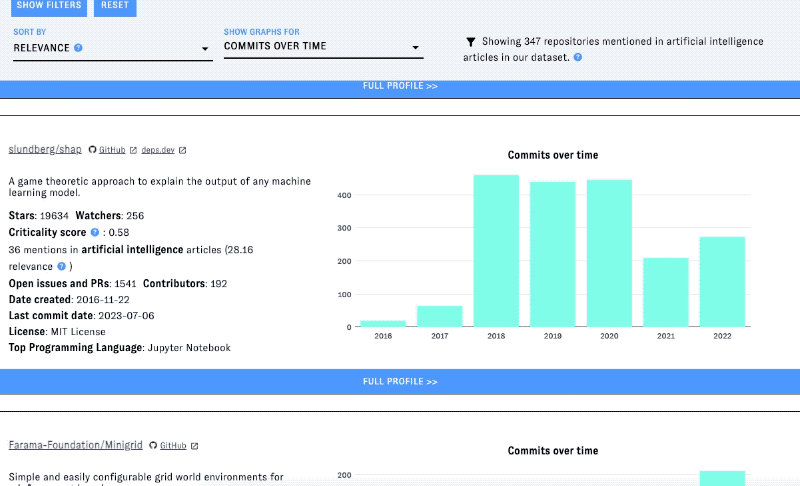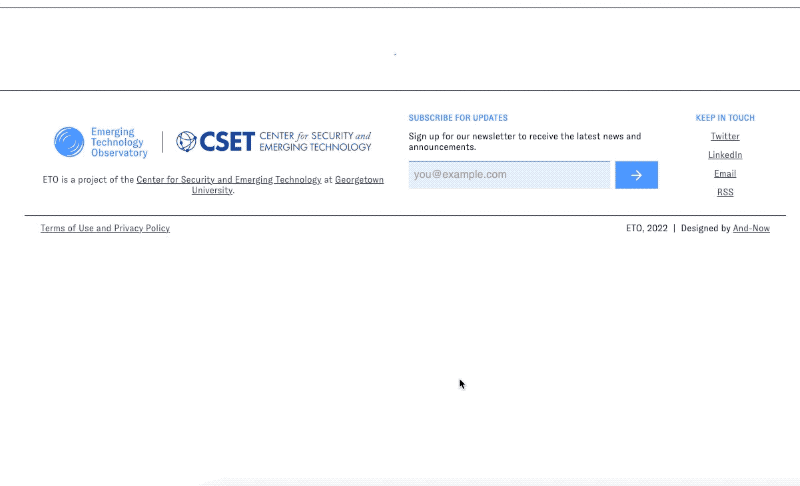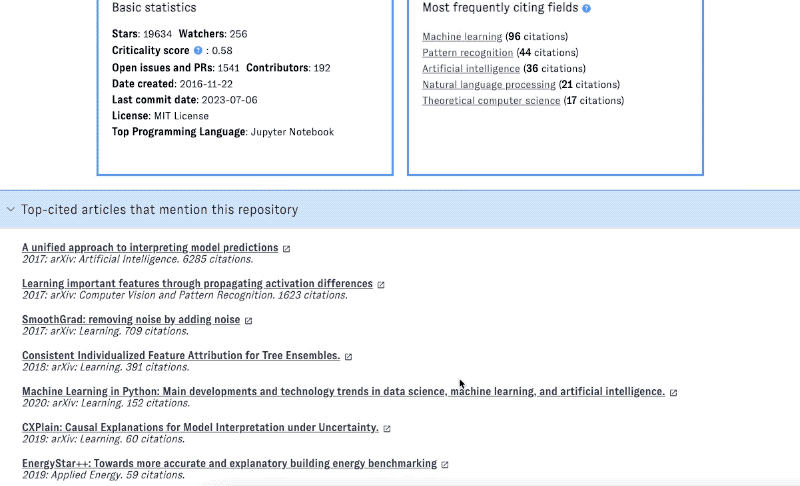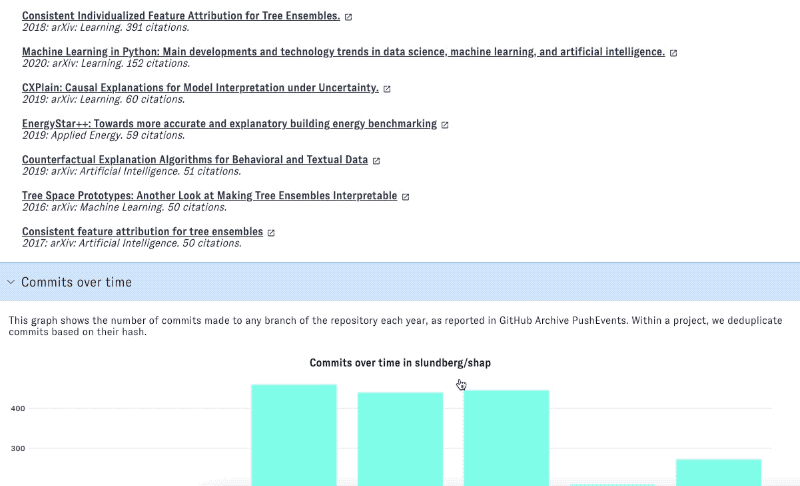
Coming back to a view
When you modify ORCA's settings, your browser's address bar will update to reflect what you're viewing. Copy the URL in order to return to the same view later:
What can I use it for?
Compare OSS projects in a particular research area according to different metrics of project activity, interest and health.
Track activity, usage, and community engagement trends over time for specific repos or for all repos in a particular field.
- Which topology-related OSS projects are engaging with the community through github issues?
- How are commits over time trending for OSS projects used by theoretical physicists?
- How much do different astronomy-related projects depend on their most active contributors?
- How many commits are being made each year to tensorflow/tensorflow?
- How many issues were opened vs closed in 2022 in SeldonIO/alibi?
- What are the most highly-cited papers that mention magic-sph/magic?
Sort and filter projects by research field, programming language, license, and various activity metrics.
What uses are not recommended?
Drawing broad conclusions about all OSS used for a particular topic or purpose. ORCA is incomplete. Before drawing conclusions based on ORCA data, consider how its limitations might affect the analysis.
Evaluating a particular OSS project's health based only on one or two ORCA metrics. For example, some projects have very few contributors yet successfully close out issues from the community and maintain a regular release schedule. Project health is complex and is dependent on multiple factors, some of which are not currently visible in ORCA.
Sources and methodology
ORCA tracks OSS projects that are used in different fields of research. This involves two subtasks: identifying projects associated with articles from different research fields and describing those projects according to different metrics.
Identifying projects associated with different research fields
In most cases, we use a largely automated process, described below, to identify articles used in different research fields. This process involves four steps: gathering research articles, grouping the articles by research field, detecting mentions of OSS projects in articles from each field, and screening the fields for final display. (A few research fields are manually associated with projects instead.)
Gathering research articles
ORCA's research literature dataset includes data from five sources:
- Article metadata (including titles and abstracts, but not full text) from the ETO Merged Academic Corpus
- Full text of articles from arXiv
- Full text of a ~300K article subset of Semantic Scholar (we expect to integrate all Semantic Scholar fulltext articles in a future update)
- Code linked to articles in Papers With Code
- Article DOIs mentioned in README files extracted from The Stack
We deduplicate and structure articles from these sources using processes similar to those described in the Merged Academic Corpus documentation.
Detecting links to OSS projects
We search the gathered data for mentions of Github repositories using the regular expression /(?i)github.com/([A-Za-z0-9-_.]+/[A-Za-z0-9-_.]*[A-Za-z0-9-_])/. We then add all of the mentions of articles in repository README files compiled by The Stack. We then extract article-repo pairs from this data - that is, a list of pairs in which the article cites the project, or the project README cites the article. We deduplicate the pairs, then use them to create the set of OSS projects tracked in ORCA, along with a set of articles associated with each project.
Associating articles with fields
Each project-citing article that has an English title and abstract, a publication date after 2010, and an abstract of over 500 characters is automatically associated with three research fields using the process described in the Merged Academic Corpus documentation. With these groupings and the citation lists compiled in the prior step, we can count how often a given OSS project is linked to articles from different fields.
Screening fields for display
Finally, we determine which of these fields will be displayed in the ORCA interface (that is, as options in the "Research Field" dropdown selector). As a general rule, the interface includes fields associated with at least ten different OSS projects, each of which is linked to at least three different articles from that field. We perform a "gut check" manual review over the most relevant projects for each field, screening out fields where these projects seem obviously unrelated or otherwise uninformative to ORCA's users. This review is meant to account for the inherent variability in our automated process for associating articles with fields, which sometimes links articles and fields that are only weakly or ambiguously connected in reality.
Manually compiled fields
In some cases, subject matter experts at CSET or elsewhere have manually compiled lists of GitHub repositories relevant to specific research fields. Rather than using our automated process for associating these fields with projects, we use expert-compiled lists in the following cases:
- Projects under the AI safety and RISC-V topics were compiled by CSET subject matter experts in early 2023.
- Projects under the Renewable energy, Energy storage, Energy systems, Energy and resource consumption, Emissions, Industrial ecology, Earth systems, Climate and earth science, Natural resources, and Sustainable development topics were compiled by the Open Sustainable Technology project. The original compilation is available through their website or GitHub repository.
- We exclude projects in the "Curated Lists" subcategory of their "Sustainable Development" compilation.
- The Renewable energy topic also includes OSS projects funded by the U.S. Department of Energy's Wind Energy Technology Office as of FY2023. These projects were compiled by Rafael Mudafort.
Limitations
Our methods for identifying research-relevant OSS projects have important limitations.
- Our automated process for linking research fields and OSS projects isn't comprehensive:
- ORCA's research literature dataset doesn't cover all research. To be included, articles must have been publicly released, and they must have English titles and abstracts. This excludes research solely in other languages as well as many articles in domains that produce little or no published research, such as product development in private industry or classified research by governments.
- ORCA's research literature dataset may not include all mentions of OSS projects in articles. The dataset lacks full text for many articles, meaning that any mentions in the full text are also missing.
- Articles are assigned to research fields using a different automated process that may be more reliable for some fields than others. Our screening process is designed in part to address this.
- ORCA doesn't include all OSS projects. We currently only cover projects on GitHub, though we hope to add other repository hosting services in the future.
- Our manual process relies on expert-curated lists of OSS projects, which may be incomplete or out of date.
- ORCA only tracks OSS projects that are directly connected to research fields. We currently don't include any data about software dependencies (other than links to deps.dev), which may include important information about how OSS projects indirectly relate to research. For example, imagine that Project X is never directly cited in astronomy research, but it's incorporated into Projects A, B, and C, all of which are heavily used by astronomers. Project X seems important to astronomy, but it would not be associated with astronomy in ORCA. We hope to include more information on dependencies in a future version of ORCA.
Describing the projects
The trends and metrics displayed for each project in ORCA are usually derived from Github Archive or GitHub API data. Here are notes for the metrics that aren't self-explanatory:
Commits over time
This counts the number of distinct commits (according to their SHA value) based on the unnested commits for PushEvents in GitHub Archive.
Mentions in different research fields
This metric is calculated using MAC data as described above.
New and returning contributors
Several metrics involve counting new and returning contributors in a given year. ORCA defines new contributors as contributors who first committed to the project repo in the year in question. Returning contributors are those who first committed to the project repo in a prior year. We identify contributors based on the names reported in GitHub Archive's PushEvents, meaning that contributions may be undercounted for individuals whose contributor names change over time.
Open issues and pull requests
The number of open issues and pull requests is retrieved from the GitHub API (the open_issues_count key). We report them together rather than separately to reflect the structure of the data we receive from the GitHub API.
OpenSSF criticality scores
OSS criticality scores are maintained by the Open Source Security Foundation, which explains: "A project's criticality score defines the influence and importance of a project. It is a number between 0 (least-critical) and 1 (most-critical)." We retrieve these scores from the criticality-score-v0-latest BigQuery dataset. Note that criticality scores assess criticality in the overall OSS ecosystem, not criticality to a particular field of research. We do not currently adjust this metric for importance to a particular research field.
PyPI downloads over time
This data comes directly from PyPI. It is only available for projects released on PyPI.Maintenance.
Relevance to different research fields
Each project is assigned a relevance score for each research field included in ORCA, other than manually compiled fields. These are TF-IDF-based scores, calculated in each case using the project repository URL as "the term" and the corpus of OSS-linked articles associated with each research field (using the process discussed above) as the "documents."
Stars over time
This metric counts new stars added (WatchEvents in GitHub Archive). It may not equal the total number of stars displayed in GitHub, as we do not keep track of star removal.
Maintenance
How is it updated?
Currently, the data is updated on an ad-hoc basis. We plan to automate monthly updates in the second half of 2023.
How can I report an issue?
Use our general issue reporting form.
Credits
- Concept: Jennifer Melot
- Design and analysis: Jennifer Melot and Zach Arnold
- Engineering: Jennifer Melot
- Review and testing: Zach Arnold, Deborah Bryant, Brian Love, Rafael Mudafort, Katharina Meyer, John Speed Meyers, Ashwin Ramaswami, Neha Singh
- Documentation: Jennifer Melot and Zach Arnold
- Maintenance: Jennifer Melot
Major change log
| 7/11/23 | Initial release |