Overview
What is this dataset?
The AGORA (AI GOvernance and Regulatory Archive) dataset is a living collection of AI-relevant laws, regulations, standards, and other governance documents from the United States and around the world. AGORA includes document text, metadata, summaries, and thematic tags to enable deep analysis of the global AI governance landscape.
How do I get it?
The dataset is available on Zenodo.
Which ETO products use it?
The AGORA dataset powers ETO's AGORA tool.
Get updates
What are its sources?
The AGORA dataset is an original Emerging Technology Observatory resource. Document text and some metadata are taken from official sources. Other metadata, summaries, and tags are produced by ETO analysts and annotators.
What are its main limitations?
- The dataset's focus on documents that directly address AI means that many AI-relevant laws, regulations, and norms are excluded by design. In particular, laws of general applicability - for example, securities regulation, civil rights law, or common-law tort doctrines - are excluded. Read more >>
- Many documents within AGORA's scope are not yet included. AGORA’s nominal scope is broader than the set of documents collected to date. In particular, the current dataset skews toward recent U.S. law and policy. New data are added regularly and we aim to broaden coverage over time. Read more >>
- Some data is machine-generated and may contain errors. We use machine learning to draft summaries of AGORA documents. The machine output is included in the dataset once generated; it may take some time after that for a human annotator to review. We prominently flag unreviewed machine-generated output in the dataset. Read more >>
- Annotators exercise judgment in applying AGORA’s scope and taxonomy, raising the risks of inconsistent screening and tagging. We try to mitigate these risks in several ways. Read more >>
What are the terms of use?
This dataset is subject to ETO's general terms of use. If you use it, please cite us.
Note that the dataset includes full text of AGORA documents, taken from sources such as government websites and repositories. Given its nature, we believe all of this material is open to non-commercial use consistent with our general terms of use, but we make no warranties.
Does it contain sensitive information, such as personally identifiable information?
No.
How do I cite it?
Please cite the "Emerging Technology Observatory AGORA dataset," including the link.
If you use AGORA to access the data, you can cite that tool instead.
Structure and content
The AGORA dataset consists of the csv tables documents, segments, collections, and authorities and a folder of text documents called fulltext.
documents
This table includes core metadata, summaries, and thematic tags for AGORA documents.
| Column name | Type | Description |
|---|---|---|
| AGORA ID | Number | A unique numerical identifier for the document. |
| Official name | Text | The full, official name of the document according to an authoritative record. If the name is extremely long, it may be truncated. |
| Casual name | Text | A colloquial name for the document, as defined in the document itself or as chosen by a screener. |
| Link to document | URL | A link to an authoritative record of the document. In virtually all cases, this means the record of the document on the official website of the authority that issued it. |
| Authority | Text | The authority that issued the document. Corresponds to a row in authorities. |
| Editor's pick | Boolean | If marked True, this record is an AGORA Editor's Pick, meaning our team thought it was especially interesting or important. |
| Collections | Text array | A screener assigns each document to one or more collections, listed here. Each collection corresponds to a row in collections. |
| Most recent activity | Text | One of the following options, as determined by a screener: "Proposed"; "Enacted" (the document has been officially approved and finalized and is in or will be entering into effect); "Defunct." |
| Most recent activity date | Date | The date on which the document attained the status indicated in Most recent activity according to official sources. |
| Proposed date | Date | The date on which the document was proposed. (If Most recent activity is Proposed, this will be the same as Most recent activity date.) |
| Annotated? | Boolean | TRUE if an annotator finished reviewing and populating fields in this table for the segment. |
| Validated? | Boolean | TRUE if a validator finished reviewing and resolving issues in fields in this table for the segment. |
| Primarily applies to the government | Boolean | TRUE if the document primarily applies to the government (e.g., an AI strategy for a government agency, or a directive to a government official to enact a regulation) rather than governing private behavior. |
| Primarily applies to the public sector | Boolean | TRUE if the document primarily applies to the private sector or civil society (e.g., conditions on the sale of AI systems, or a law banning individuals from using AI for specific purposes). A document that (implicitly or explicitly) applies to government actors as well as actors outside government would be assigned a value of FALSE for this field. |
| Short summary | Text | A skimmable (1-2 sentence length) summary of the AI-related content of the document. |
| Long summary | Text | A detailed (1-2 paragraph equivalent) summary of the AI-related content of the document. |
| Segment-level tags | Text array | For documents that were segmented for detailed annotation (the typical case), this field lists all thematic tags applicable to one or more of the document's segments. |
| Document-level tags | Text array | For documents that were not segmented for detailed annotation (a minority of AGORA documents), this field lists all thematic tags applicable to any part of the document as a whole. |
| Summaries and tags include unreviewed machine output | Boolean | TRUE if any summary or tag fields in this table include content generated by a language model and the document has not yet been annotated by a human (i.e., Annotated? is FALSE). |
| Official plaintext retrieved | Date | If fulltext for the document is available in fulltext, this field lists the date on which the fulltext was retrieved. |
| Official plaintext source | URL | If fulltext for the document is available in fulltext, this field lists the source of the fulltext. |
| Official plaintext unavailable/infeasible | Boolean | TRUE if fulltext for the document could not be retrieved in machine-readable form. |
| Official pdf source | URL | If a pdf of the document is available in fulltext, this field lists the source of the pdf. |
| Official pdf retrieved | Date | If a pdf of the document is available in fulltext, this field lists the date of retrieval. |
| Number of segments created | Number | The number of segments into which the document was divided for detailed annotation. If 0, the document was not segmented. |
| [subsequent fields] | boolean | The remaining fields in this table disaggregate the thematic tags listed in Segment-level tags or Document-level tags, as applicable, for ease of analysis. Each field corresponds to one tag and indicates whether the tag does or does not apply with the values TRUE and FALSE, respectively. |
segments
This table includes metadata, summaries, and thematic tags for individual segments of AGORA documents.
| Column name | Type | Description |
|---|---|---|
| Document ID | number | |
| Segment position | number | The position of the segment within the document relative to other segments. |
| Text | text | The text of the segment. (Use AGORA text with caution.) |
| Tags | text array | A list of thematic tags applicable to the segment, standing alone (i.e., without considering cross-references or the definitions of defined terms that appear in the segment). |
| Summary | text | A short summary of the AI-related content of the segment. |
| Non-operative | boolean | TRUE if an annotator determined that none of the text of the segment was operative, i.e., having practical effect. Examples of non-operative text include tables of contents and explanatory preambles. |
| Not AI-related | boolean | TRUE if an annotator determined that none of the text of the segment related to AI (taking into account the definitions of defined terms and cross-references to other parts of the relevant document). |
| Segment annotated | boolean | TRUE if an annotator finished reviewing and populating fields in this table for the segment. |
| Segment validated | boolean | TRUE if a validator finished reviewing and resolving issues in fields in this table for the segment. |
| Summaries and tags include unreviewed machine output | boolean | TRUE if either Summary or Tags include content generated by a language model and the segment has not yet been annotated by a human (i.e., Segment annotated is FALSE). |
| [subsequent fields] | boolean | The remaining fields in this table disaggregate the thematic tags listed in tags for ease of analysis. Each field corresponds to one tag and indicates whether the tag does or does not apply with the values TRUE and FALSE, respectively. |
collections
This table lists and describes the collections AGORA documents are assigned.
| Column name | Type | Description |
|---|---|---|
| Name | text | The name of the collection. |
| Description | text | A short description of the collection. |
authorities
This table lists and describes the authorities associated with AGORA documents.
| Column name | Type | Description |
|---|---|---|
| Name | text | The name of the authority. |
| Jurisdiction | text | The legal jurisdiction corresponding to or containing the authority (for example, "United States" for the authority "California"). |
| Parent authority | text | If the authority is part of a group of similar authorities, a parent authority group is specified (for example, "State governments" for the authority "California"). |
fulltext
The "fulltext" folder includes individual files with the full text of each AGORA document for which full text has been collected. Each file is labeled with the AGORA ID of the corresponding document.
Sources and methodology
Scope
AGORA's nominal scope
The AGORA dataset includes laws, regulations, standards, and similar documents that directly and substantively address the development, deployment, or use of artificial intelligence technology. The intent of this scoping definition is to encompass the large majority of documents created by lawmakers, regulators, and standard-setters in direct response to advances in modern machine learning and related technologies.
Applying subjective elements of this definition, such as “directly and substantively,” inevitably involves judgment. When screening documents for inclusion in AGORA, we try to constrain this judgment by defining heuristics.
Critically, the requirement that documents “directly” address artificial intelligence generally excludes laws predating the rise of modern machine learning, even if they are broad enough in scope to bear on AI. We draw this line to ensure that AGORA’s scope is manageable in practice and to reinforce the dataset’s emphasis on policies created in response to 21st century developments in AI, rather than the entire set of policy documents that may affect individual sectors and governance writ large. Note, however, that more recent documents that tailor these broad laws to the specific context of AI would qualify for inclusion in AGORA. For example, while the Civil Rights Act of 1964 would not be included in AGORA, a related federal regulation or guidance document applying the Act to racially discriminatory AI is within AGORA’s scope.
Current coverage
AGORA’s nominal scope is broader than the set of documents collected to date. In particular, the current dataset skews toward U.S. law and policy. New data are added regularly and we plan to broaden coverage over time.
For now, AGORA aims to include the following documents (to the extent they are within AGORA's scope) with a lag of no more than a few months:
- United States federal documents - all enacted and proposed federal laws since 2020; all enacted and proposed federal regulations since 2020; all enacted executive orders since 2020; other agency documents of major popular or scholarly interest.
- United States state documents - currently collected ad hoc; not necessarily comprehensive or representative.
- Other documents - currently collected ad hoc; not necessarily comprehensive or representative.
Our next priorities are to broaden coverage of U.S. state documents, with the aim of including all enacted, in-scope state laws on a going-forward basis, and to broaden coverage of Chinese central government documents and major corporate commitments. We will update this section as we make progress toward these goals.
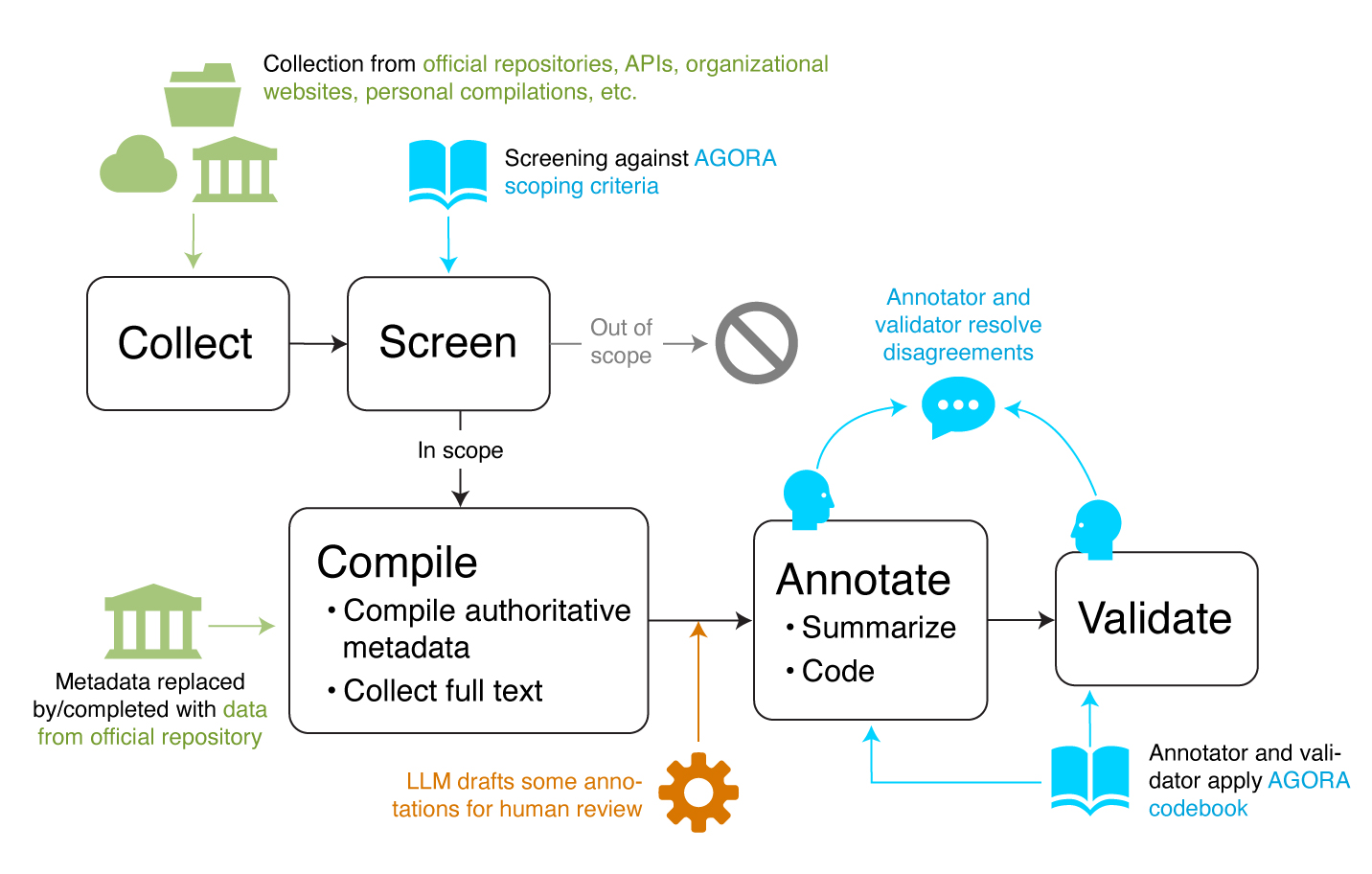
Collection, screening, and initial enrichment
Candidate documents for inclusion in AGORA are currently collected manually or using semi-automated means (e.g., saved queries against larger datasets) from a wide range of official and unofficial sources, reflecting the decentralized, largely ad-hoc status of current AI governance tracking. The most common sources include official, general-purpose regulatory compilations, such as the Congress.gov service for United States federal legislation and the Federal Register for United States federal regulation. Human screeners review these sources (periodically, in the case of sources that update) and assess each document against the AGORA scoping definition.
Screeners first determine whether documents are within AGORA's scope. Only in-scope documents are included in the AGORA dataset. For documents determined to be in scope, screeners locate the authoritative text of the document (for example, on the official website of the United States Congress or a state legislature) and use it to populate basic metadata such as title and date of introduction. Whenever feasible, they also archive a plaintext copy of the document and divide it into shorter segments (often, but not always, corresponding to sections, subsections, or similar divisions already present in the text) for granular annotation.
Annotators also identify “packages,�” or larger, thematically diverse documents containing AI-related portions amidst other, AI-unrelated material. A typical example is the annual National Defense Authorization Act (NDAA) in the United States, a massive, largely AI-unrelated law with some diverse AI-related provisions sprinkled throughout in recent years. NDAAs and other such packages are divided into conceptually discrete AGORA documents, corresponding to sections, subsections, or other subdivisions in the packages, according to standing guidance.
Finally, screeners identify a canonical AGORA authority for the document and assign it to one or more thematic collections. AGORA authorities and collections are listed in the authorities and collections tables, respectively.
Provisional annotation using a language model
After screening, a language model processes the full text of each in-scope document and generates draft annotations for human review. We use an "off-the-shelf" commercial LLM (accessed via API) and ETO-developed prompts.
At present, the language model is used only to generate draft summaries of each document as a whole and each segment in the document. We have found that machine-generated summaries of AGORA documents are generally reliable and useful. Regardless, we flag unreviewed machine-generated output in the dataset, and affected documents can easily be removed, if desired, by filtering on the flag fields.
In the future, we may also use language models to generate provisional thematic tags for segments.
Annotation and validation
Using the basic metadata and authoritative text compiled during the screening process, ETO annotators develop summaries and thematic tags for each in-scope document - or review and revise the machine-generated drafts, as available.
For tagging, the annotators use an extensive codebook that includes general guidance and specific definitions for each thematic tag. Tags are applied segment by segment. A custom-built Airtable interface structures the annotator workflow and facilitates quick and accurate annotation.
AGORA’s summaries are meant mainly to help users skim and sift, rather than as an analytic resource in themselves; the codebook provides brief instructions for short- and long-form summaries, but significant discretion is left to annotators.
After initial annotation, a second annotator (designated the “validator”) reviews each document in full and discusses any disagreements with the initial annotator. Note that these are not fixed roles; each AGORA annotator serves as initial annotator on some documents and as validator on others.
Once all issues identified in validation have been resolved, the document’s record, consisting of validated metadata, short and long summaries, and thematic tags, is marked complete.
The AGORA thematic taxonomy
AGORA includes a thematic taxonomy that is inspired by scholarly and policy literature, but intended to be useful to a wide range of potential users and reasonably intuitive to both those users and AGORA annotators. The taxonomy was drafted by an interdisciplinary team with training in law, data engineering, public policy, political science, AI governance, and quantitative and qualitative social science methods, with input from potential users in government, academia, and the private sector, and has been refined iteratively based on annotator and user feedback.
The taxonomy consists of discrete concepts (“tags”) organized into five domains:
- Risk factors governed: The characteristics addressed by the document that affect AI systems’ propensity to cause harm, closely related to ethical concerns. AGORA’s risk tags are adapted from the risk categories outlined in the widely-used AI Risk Management Framework issued by the U.S. National Institute of Standards and Technology.
- Harms addressed: The potential harmful consequences of the development or use of AI that this document means to prevent. Per AGORA’s definitions, “harms” are the consequences of “risks” (prior bullet). For example, an AI system that is insecure or biased (risk characteristics) might end up causing harm to physical health or financial loss (harms). AGORA’s harm tags are adapted from categories of harm developed by CSET researchers for use with the AI Incident Database.
- Governance strategies: The means provided in the document to address, assess, or otherwise act with respect to the development, deployment, or use of AI. These are essentially the proposed solutions to the policy problems or goals articulated. AGORA’s governance strategy tags were developed iteratively by the AGORA leadership team over the first several months of annotation.
- Incentives for compliance: The types of incentives provided for people, organizations, etc., to comply with the requirements of the document. This small group of tags covers positive and negative incentives commonly seen in AI-related statutes and regulations, such as subsidies and fines, respectively.
- Application domains addressed: Any economic or social sectors, such as healthcare or defense, specifically addressed in the document as contexts for AI development, deployment, or use. AGORA’s application tags are adapted from the TINA industry taxonomy used in prior analyses of AI-related investment and are comparable in granularity to 2-digit NAICS codes, with one exception: given significant attention to the use of AI by governments in particular, the code for government applications of AI is divided into subcategories, allowing for more specific analysis.
Annotators read each AGORA document in full, then decide whether each of the 77 codes in the AGORA taxonomy applies at any point in the document, based on the definition and (where available) examples and keywords provided in the codebook. In deciding, annotators are instructed to consider only the operative text of each document; to focus on what the document explicitly states or clearly and directly implies; and to ignore material unrelated to artificial intelligence.
Known limitations
- The dataset's focus on documents that directly address AI means that many AI-relevant laws, regulations, and norms are excluded by design. In particular, laws of general applicability - for example, securities regulation, civil rights law, or even common-law tort doctrines have implications for modern AI. However, this body of often older, AI-relevant general law is a potentially unbounded set, and the applicability of any particular document may be debated. Accordingly, we exclude these documents from AGORA’s scope. Though this makes the dataset less comprehensive of the overall AI governance landscape, it reduces uncertainty over the bounds of the resource. Also, AI-focused implementations of more general laws - such as agency regulations or guidance explaining how broad existing authorities will be applied to AI - are in scope for the dataset, reducing the impact of the exclusion. Nonetheless, this limitation means analyzing the dataset on its own cannot replace careful region-, context-, and sector-specific analysis of regulations relevant to particular groups, organizations, or AI use cases, though it can enhance such analysis.
- Many other documents within AGORA's scope are not yet included. AGORA’s nominal scope is broader than the set of documents collected to date. In particular, the current dataset skews toward U.S. law and policy. We are experimenting with automation and seeking more resources to increase processing volume and multi-language coverage. In the meantime, we have focused annotators’ efforts on especially high-profile or consequential documents (e.g., adopted rather than proposed policies) and on sets of documents of particular interest to current AGORA stakeholders.
- Some data is machine-generated and may contain errors. We currently use machine learning to draft summaries of AGORA documents. The machine output is included in the dataset once generated; it may take some time after that for a human annotator to review. We have found that the machine-generated summaries of AGORA documents are generally reliable and useful. Regardless, we flag unreviewed machine-generated output in the dataset, and affected documents can easily be removed, if desired, by filtering on the relevant fields.
- Annotators exercise judgment in applying AGORA’s scope and taxonomy, raising the risks of inconsistent screening and tagging. To mitigate these risks, we provide detailed conceptual definitions, along with examples and decision heuristics. Further, we implement a dual annotation process (initial annotation followed by validation and reconciliation) for each document, with disagreements elevated to AGORA leadership and resolved according to defined procedures. (Records pending validation are included in the dataset, but can easily be excluded, if desired, by filtering on the validation fields in the relevant tables.) Finally, we maintain a searchable central repository of prior questions and answers and make it accessible to all AGORA annotators online.
- Some documents are thematically tagged as a whole, rather than segment-by-segment; in these cases, it may not be immediately clear which parts of the documents justify which tags.
- AGORA fulltext files are unofficial copies of the underlying documents, collected by our screeners for research purposes and users' convenience. These files have been reformatted and may be out of date or otherwise diverge from official versions, particularly in the case of documents that were not finalized at the time text was collected (e.g., bills of Congress not yet signed into law). Use AGORA fulltext with caution. For official text, visit the original sources specified in the document's AGORA metadata.
Maintenance
How are the data updated?
Records are periodically added to the public AGORA dataset (and the web interface) using an automated script. We add records as soon as they are screened, then update them as they are annotated and validated. This means that some records in the dataset often change over time, and many include unvalidated and/or machine-generated content. If desired, this content can be disregarded by filtering on the relevant fields in the data tables.
Credits
- Schema, codebook and taxonomy: Zach Arnold, Daniel Schiff, Kaylyn Jackson Schiff
- Editors (current and former): Lindsay Jenkins, Ashley Lin, Konstantin Pilz, Adrian Thinnyun
- Annotators (current and former): Tasneem Ahmed, Noelia Alvarez, Zoe Borden, Eileen Chen, Ogadinma Enwereazu, Ari Filler, Evan Glenn, Diya Kalavala, Mallika Keralavarma, Kieran Lee, Sophia Lu, Myriam Lynch, Anjali Nookala, Erin Oppel, Esther Serger, Maya Snyder, Niel Swanepoel, Jayan Srinivasan, Alina Thai, Julio Wang
- Documentation: Zach Arnold, Daniel Schiff
Major change log
| 10/1/24 | Initial release |