Overview
What is this tool?
AGORA (AI GOvernance and Regulatory Archive) is an exploration and analysis tool for AI-relevant laws, regulations, standards, and other governance documents from the United States and around the world. Drawing on original ETO data, AGORA includes summaries, document text, thematic tags, and filters to help you quickly discover and analyze key developments in AI governance. Its easy-to-use interface includes plain-English summaries, detailed metadata, and full text for hundreds of AI-focused laws and policies, with new data being added continuously.
What can I use it for?
- Find recent laws, policies, standards and similar documents from a wide range of jurisdictions and organizations, including governments as well as private companies.
- Quickly get up to speed on specific documents of interest using AGORA's plain-English summaries - or dive into the full text of any document.
- Sort and filter documents by criteria including keyword, date, jurisdiction, and enactment status.
- Use AGORA's original taxonomy to find documents related to specific AI governance themes, from evaluation and information disclosure to public investment.
- Identify documents that address specific applications of AI, such as medicine, finance, or military uses.
Get updates
What are its most important limitations?
- AGORA's focus on documents that directly address AI means that many AI-relevant laws, regulations, and norms are excluded by design. In particular, laws of general applicability - for example, securities regulation, civil rights law, or common-law tort doctrines - are excluded. Read more >>
- Some documents are missing. AGORA’s nominal scope is broader than the set of documents collected to date. In particular, the current tool skews toward recent U.S. law and policy. New data are added regularly and we aim to broaden coverage over time. Read more >>
- Some data is machine-generated and may contain errors. We use machine learning to draft summaries of AGORA documents. The machine output is included in the interface once generated; it may take some time after that for a human annotator to review. We prominently flag unreviewed machine-generated output in the interface. Read more >>
What are its sources?
The AGORA interface builds on ETO's original AGORA dataset. Read more >>
Does it contain sensitive information, such as personally identifiable information?
No.
What are the terms of use?
The AGORA tool and data are subject to ETO's general terms of use. If you use the tool, please cite us.
Note that the dataset includes full text of AGORA documents, taken from sources such as government websites and repositories. Given its nature, we believe all of this material is open to non-commercial use consistent with our general terms of use, but we make no warranties.
How do I cite it?
If you use data from AGORA in your work, please cite "Emerging Technology Observatory AGORA" and include the link to the tool.
Using AGORA
How do I use it?
AGORA has two main views: a default feed-style view meant for browsing and filtering documents, and a detail view for examining individual documents and their metadata. There's also a simple page for browsing AGORA by thematic collections.
Getting started in default view
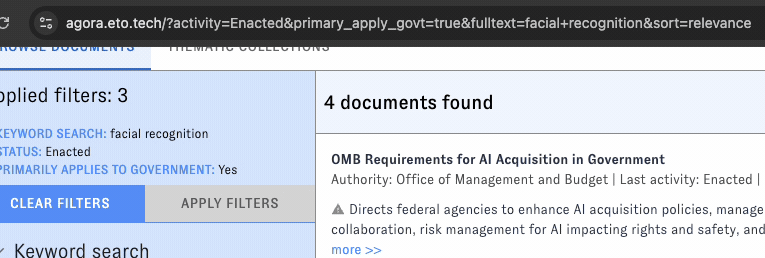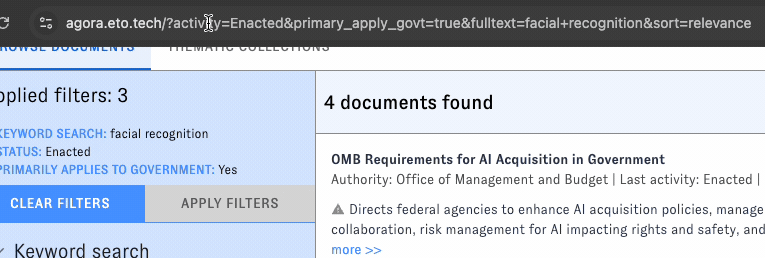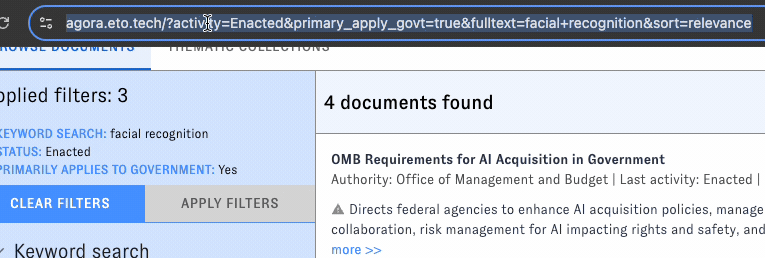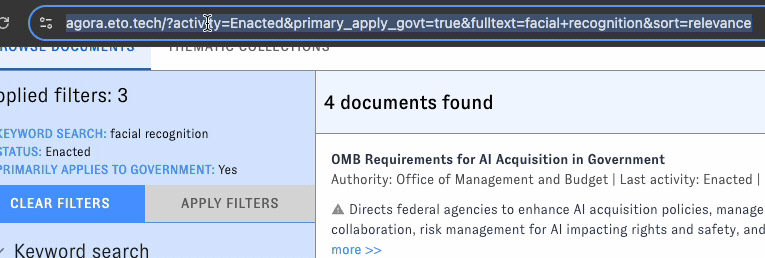
AGORA's default view displays a filterable feed of documents. Filters are organized into groups in the left-hand sidebar; click on the headers to switch between groups.
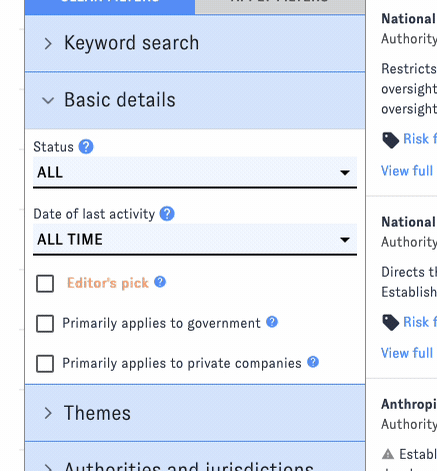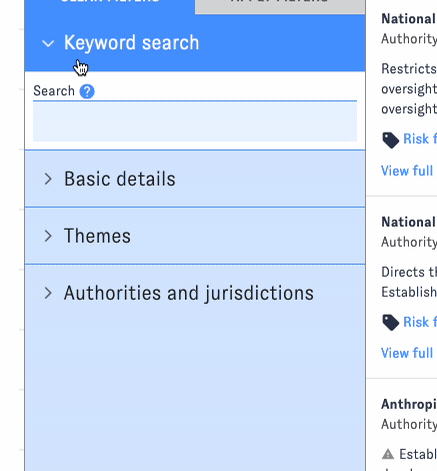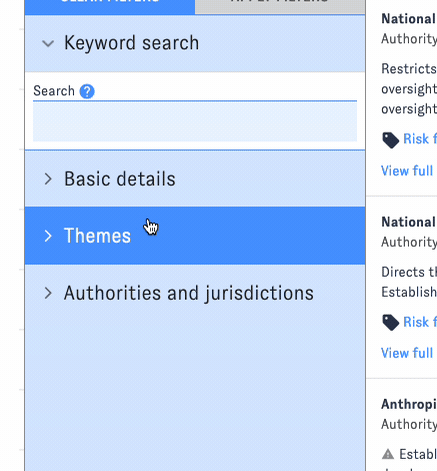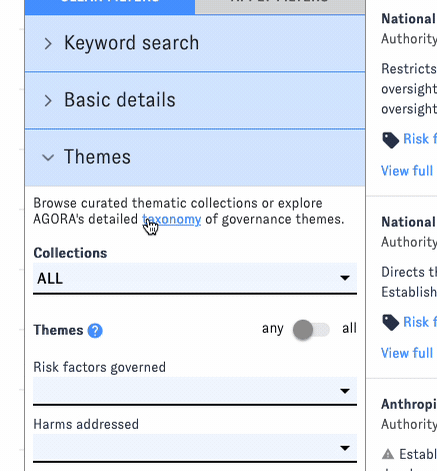
You can apply filters one at a time, or combine filters from different groups into a more complex query. Click "Apply Filters" to view the results. (The interface will remind you which filters you've selected.) To reset the search, click "Clear Filters."

As filters and view options are modified, the URL will update to reflect the changes. Copy the URL to relaunch the same search later.
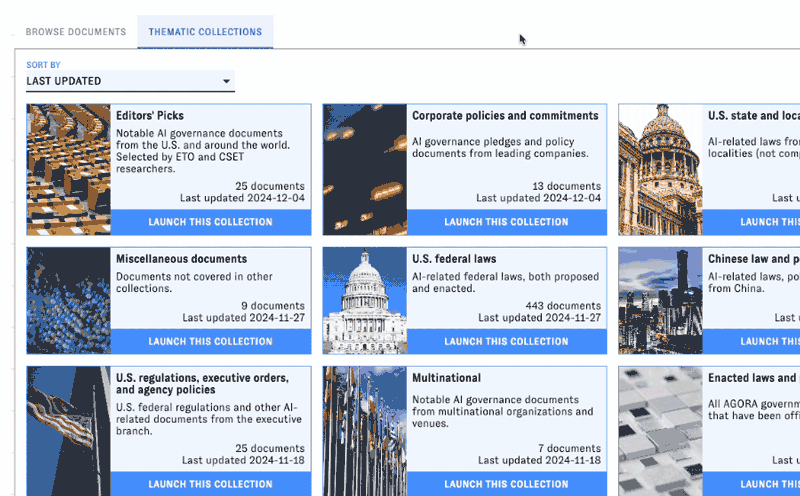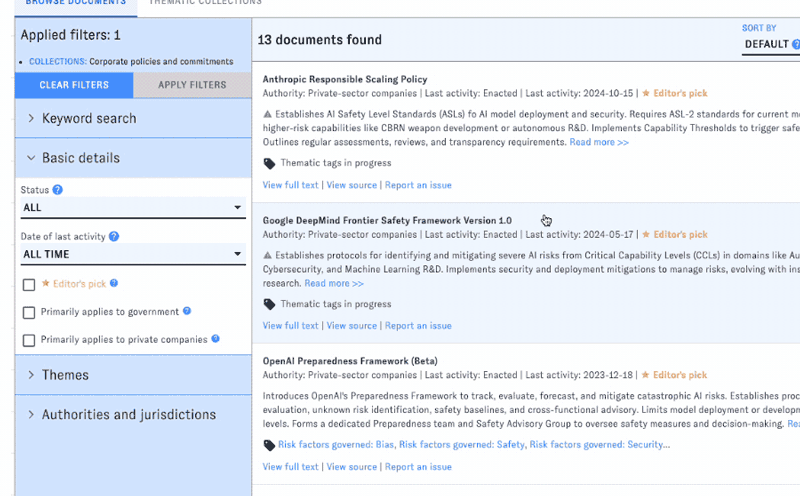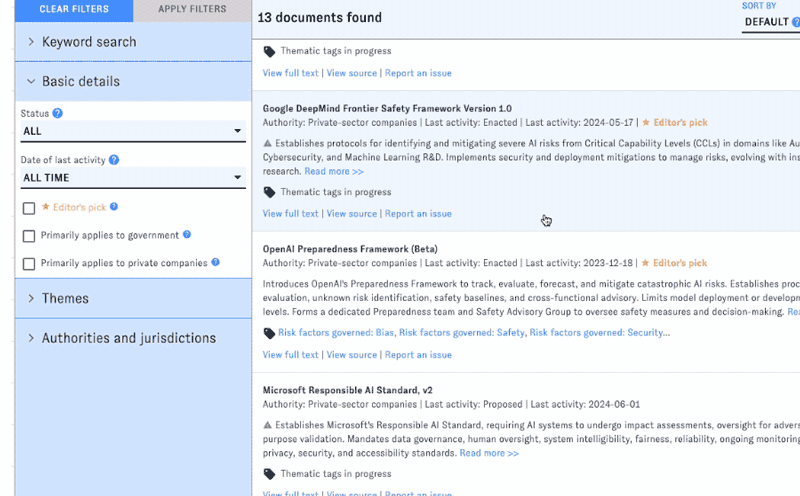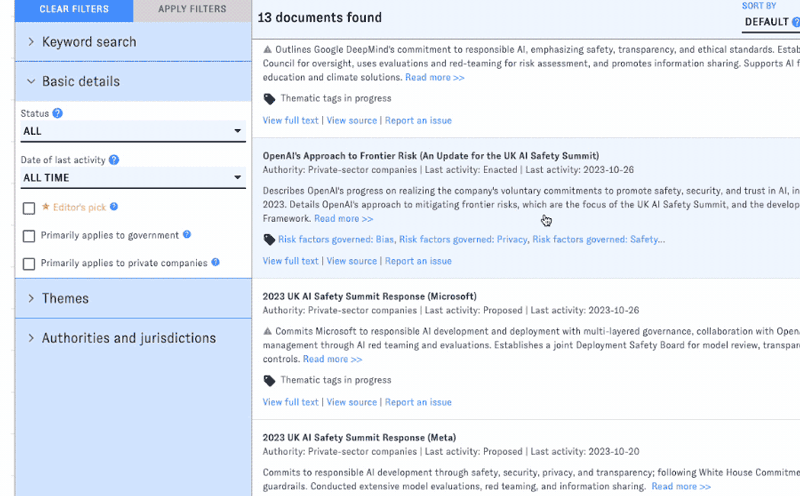
Browsing by collection
AGORA organizes documents into thematic collections (among many other ways). There's a dropdown filter for collections in the filter sidebar (under "Themes"), but you can also visually browse these collections using the "Thematic collections" tab off of the default view:
Clicking on a collection will populate the feed view with that collection's documents.
Going deeper: detail view
Clicking on an item from the main view will bring you into detail view, which provides short and long summaries, selected metadata, thematic tags, and full text for the document you clicked on.

What can I use it for?
- Find recent laws, policies, standards and similar documents from a wide range of jurisdictions and organizations, including governments as well as private companies.
- Quickly get up to speed on specific documents of interest using AGORA's plain-English summaries and metadata - or dive into the full text of any document.
- Show me a summary of the Blueprint for an AI Bill of Rights.
- When were China's regulations on recommendation algorithms enacted?
- What does the Colorado AI Act do? Show me the full text.
- Sort and filter documents by criteria including keyword, date, jurisdiction, and collection.
- Use AGORA's original taxonomy to find documents related to specific AI governance themes, from evaluation and information disclosure to public investment.
- Identify documents that address specific applications of AI.
- Show me AGORA docs that address AI uses in agriculture. How about government use of AI? How about government use of AI specifically for military or public safety applications?
Which uses are not recommended?
- Drawing broad conclusions about jurisdictions or document types that AGORA does not cover comprehensively. AGORA's scope is limited. It offers comprehensive coverage of some types of documents, such as recent AI-related legislation in the United States Congress, but coverage in other domains is less comprehensive. For example, the relatively few Chinese or British documents in AGORA can provide useful case studies about AI governance in those countries and illustrate potential themes for further study, but wouldn't be valid to draw broad conclusions about AI governance in those countries based only on the limited documents AGORA includes.
- Tracking up-to-the-minute developments. AGORA is designed for diverse audiences interested in AI governance. We are not currently prioritizing features used mainly by professional legislative trackers, such as real-time updating, direct syncing to official databases, or archiving and comparison of successive versions of legislation in progress. (If these features would be especially important to you, please let us know - you could help change our minds!)
- Confirming one's own legal obligations. We hope that AGORA can help people and organizations understand AI regulations and governance documents that may apply to them. Nonetheless, AGORA on its own is not a compliance guide. All AGORA regulatory text, metadata, and interpretation in AGORA is provided for convenience only and may differ from official sources. Nothing in AGORA is intended to be legal advice.
Sources and methodology
The AGORA interface builds on ETO's original AGORA dataset, a living collection of AI-relevant laws, regulations, standards, and other governance documents from the United States and around the world. Visit the dataset's documentation to learn more about this dataset and how it's maintained.
Maintenance
How is it updated?
AGORA updates automatically when the underlying AGORA dataset updates, typically several times a month.
How can I report an issue?
Use our general issue reporting form.
Credits
- Concept and design: Zach Arnold, Brian Love, Niharika Singh
- Engineering: Jennifer Melot, Brian Love, Niharika Singh
- Documentation: Zach Arnold
Major change log
| 6/28/24 | Beta release |
| 12/11/24 | Changes for full release, including updated UI and restructured documentation |